



















































![CCTV-17農業農村 | [中(zhōng)國(guó)三農報道]中(zhōng)國(guó)科(kē)學(xué)院植被病蟲害遙感監測與預測系統升級版發布](static/picture/630c32e37f65b.png)




































深度學(xué)習有(yǒu)很(hěn)好的表現,引領了第三次人工(gōng)智能(néng)的浪潮。目前大部分(fēn)表現優異的應用(yòng)都用(yòng)到了深度學(xué)習,大紅大紫的 AlphaGo 就使用(yòng)到了深度學(xué)習。
本文(wén)将詳細的給大家介紹深度學(xué)習的基本概念、優缺點和主流的4個典型算法。
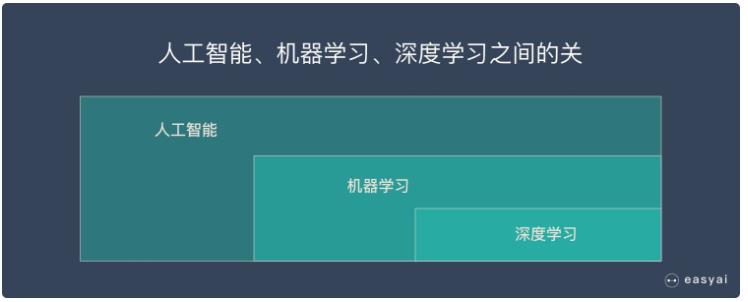
深度學(xué)習、神經網絡、機器學(xué)習、人工(gōng)智能(néng)的關系
深度學(xué)習、機器學(xué)習、人工(gōng)智能(néng)
簡單來說:
深度學(xué)習是機器學(xué)習的一個分(fēn)支(最重要的分(fēn)支)
機器學(xué)習是人工(gōng)智能(néng)的一個分(fēn)支
目前表現最好的一些應用(yòng)大部分(fēn)都是深度學(xué)習,正是因為(wèi)深度學(xué)習的突出表現,引發了人工(gōng)智能(néng)的第三次浪潮。詳情可(kě)以看《人工(gōng)智能(néng)的發展史——3次 AI 浪潮》
深度學(xué)習、神經網絡
深度學(xué)習的概念源于人工(gōng)神經網絡的研究,但是并不完全等于傳統神經網絡。
不過在叫法上,很(hěn)多(duō)深度學(xué)習算法中(zhōng)都會包含”神經網絡”這個詞,比如:卷積神經網絡、循環神經網絡。
所以,深度學(xué)習可(kě)以說是在傳統神經網絡基礎上的升級,約等于神經網絡。

大白話解釋深度學(xué)習
看了很(hěn)多(duō)版本的解釋,發現李開複在《人工(gōng)智能(néng)》一書中(zhōng)講的是最容易理(lǐ)解的,所以下面直接引用(yòng)他(tā)的解釋:
我們以識别圖片中(zhōng)的漢字為(wèi)例。
假設深度學(xué)習要處理(lǐ)的信息是“水流”,而處理(lǐ)數據的深度學(xué)習網絡是一個由管道和閥門組成的巨大水管網絡。網絡的入口是若幹管道開口,網絡的出口也是若幹管道開口。這個水管網絡有(yǒu)許多(duō)層,每一層由許多(duō)個可(kě)以控制水流流向與流量的調節閥。根據不同任務(wù)的需要,水管網絡的層數、每層的調節閥數量可(kě)以有(yǒu)不同的變化組合。對複雜任務(wù)來說,調節閥的總數可(kě)以成千上萬甚至更多(duō)。水管網絡中(zhōng),每一層的每個調節閥都通過水管與下一層的所有(yǒu)調節閥連接起來,組成一個從前到後,逐層完全連通的水流系統。
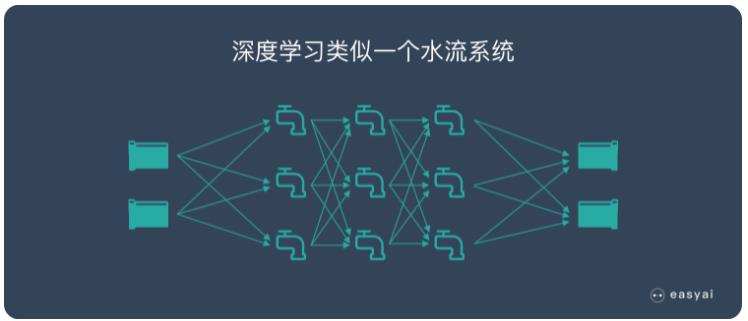
那麽,計算機該如何使用(yòng)這個龐大的水管網絡來學(xué)習識字呢(ne)?
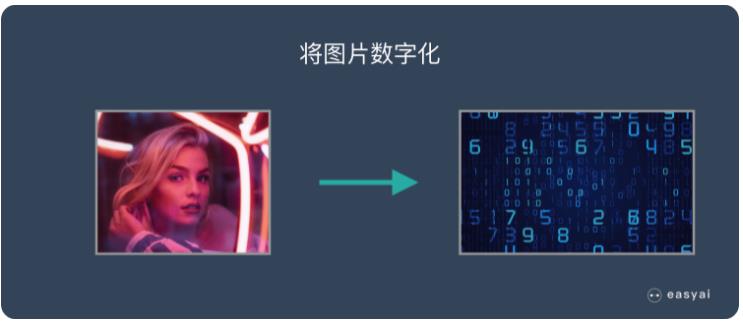
比如,當計算機看到一張寫有(yǒu)“田”字的圖片,就簡單将組成這張圖片的所有(yǒu)數字(在計算機裏,圖片的每個顔色點都是用(yòng)“0”和“1”組成的數字來表示的)全都變成信息的水流,從入口灌進水管網絡。
所以,深度學(xué)習可(kě)以說是在傳統神經網絡基礎上的升級,約等于神經網絡。
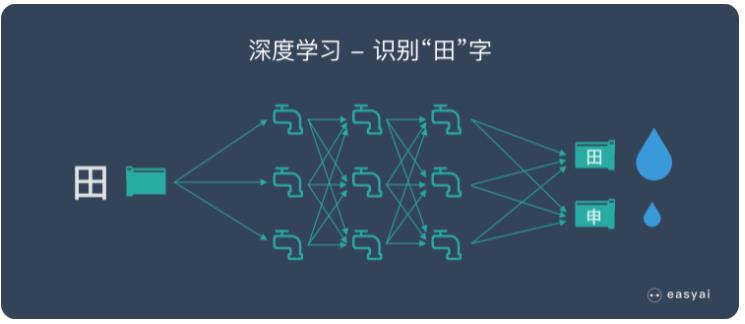
我們預先在水管網絡的每個出口都插一塊字牌,對應于每一個我們想讓計算機認識的漢字。這時,因為(wèi)輸入的是“田”這個漢字,等水流流過整個水管網絡,計算機就會跑到管道出口位置去看一看,是不是标記由“田”字的管道出口流出來的水流最多(duō)。如果是這樣,就說明這個管道網絡符合要求。如果不是這樣,就調節水管網絡裏的每一個流量調節閥,讓“田”字出口“流出”的水最多(duō)。
這下,計算機要忙一陣了,要調節那麽多(duō)閥門!好在計算機的速度快,暴力的計算加上算法的優化,總是可(kě)以很(hěn)快給出一個解決方案,調好所有(yǒu)閥門,讓出口處的流量符合要求。
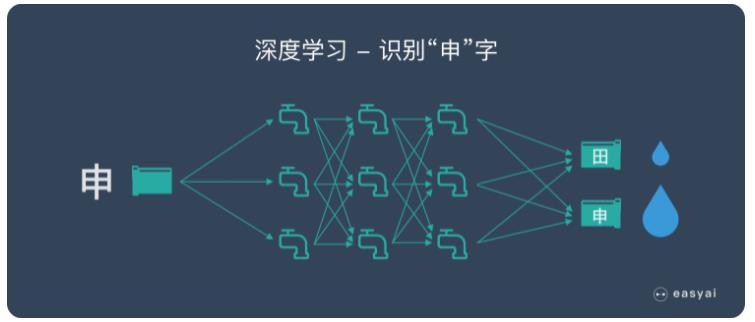
下一步,學(xué)習“申”字時,我們就用(yòng)類似的方法,把每一張寫有(yǒu)“申”字的圖片變成一大堆數字組成的水流,灌進水管網絡,看一看,是不是寫有(yǒu)“申”字的那個管道出口流水最多(duō),如果不是,我們還得再調整所有(yǒu)的閥門。這一次,要既保證剛才學(xué)過的“田”字不受影響,也要保證新(xīn)的“申”字可(kě)以被正确處理(lǐ)。
如此反複進行,知道所有(yǒu)漢字對應的水流都可(kě)以按照期望的方式流過整個水管網絡。這時,我們就說,這個水管網絡是一個訓練好的深度學(xué)習模型了。當大量漢字被這個管道網絡處理(lǐ),所有(yǒu)閥門都調節到位後,整套水管網絡就可(kě)以用(yòng)來識别漢字了。這時,我們可(kě)以把調節好的所有(yǒu)閥門都“焊死”,靜候新(xīn)的水流到來。
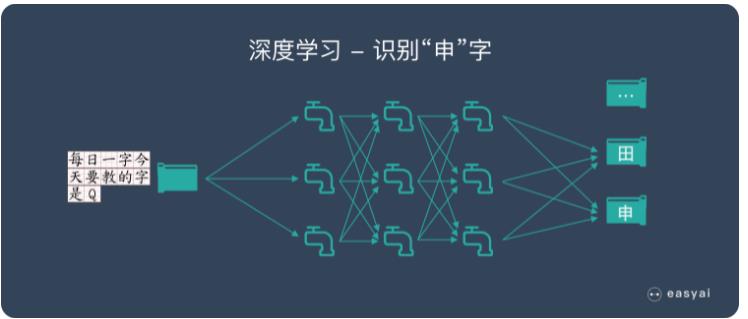
與訓練時做的事情類似,未知的圖片會被計算機轉變成數據的水流,灌入訓練好的水管網絡。這時,計算機隻要觀察一下,哪個出水口流出來的水流最多(duō),這張圖片寫的就是哪個字。
深度學(xué)習大緻就是這麽一個用(yòng)人類的數學(xué)知識與計算機算法構建起來的整體(tǐ)架構,再結合盡可(kě)能(néng)多(duō)的訓練數據以及計算機的大規模運算能(néng)力去調節内部參數,盡可(kě)能(néng)逼近問題目标的半理(lǐ)論、半經驗的建模方式。
傳統機器學(xué)習 VS 深度學(xué)習
傳統機器學(xué)習和深度學(xué)習的相似點
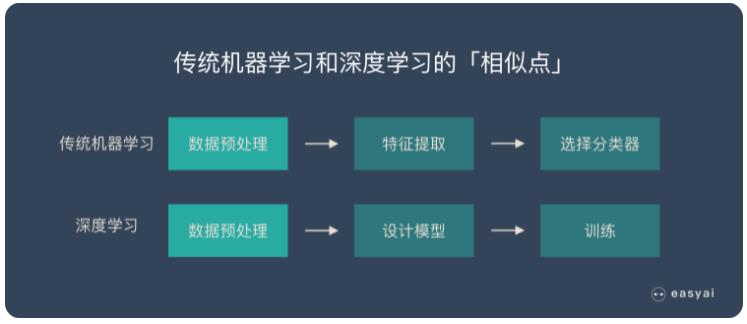
在數據準備和預處理(lǐ)方面,兩者是很(hěn)相似的。
他(tā)們都可(kě)能(néng)對數據進行一些操作(zuò):
數據清洗
數據标簽
歸一化
去噪
降維
對于數據預處理(lǐ)感興趣的可(kě)以看看《AI 數據集最常見的6大問題(附解決方案)》
傳統機器學(xué)習和深度學(xué)習的核心區(qū)别
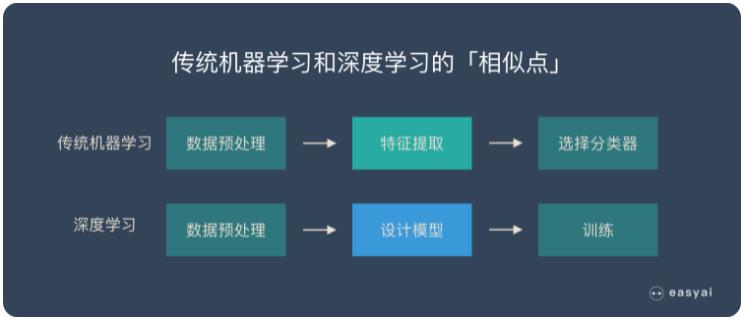
傳統機器學(xué)習的特征提取主要依賴人工(gōng),針對特定簡單任務(wù)的時候人工(gōng)提取特征會簡單有(yǒu)效,但是并不能(néng)通用(yòng)。
深度學(xué)習的特征提取并不依靠人工(gōng),而是機器自動提取的。這也是為(wèi)什麽大家都說深度學(xué)習的可(kě)解釋性很(hěn)差,因為(wèi)有(yǒu)時候深度學(xué)習雖然能(néng)有(yǒu)好的表現,但是我們并不知道他(tā)的原理(lǐ)是什麽。
深度學(xué)習的優缺點

優點1:學(xué)習能(néng)力強
從結果來看,深度學(xué)習的表現非常好,他(tā)的學(xué)習能(néng)力非常強。
優點2:覆蓋範圍廣,适應性好
深度學(xué)習的神經網絡層數很(hěn)多(duō),寬度很(hěn)廣,理(lǐ)論上可(kě)以映射到任意函數,所以能(néng)解決很(hěn)複雜的問題。
優點3:數據驅動,上限高
深度學(xué)習高度依賴數據,數據量越大,他(tā)的表現就越好。在圖像識别、面部識别、NLP 等部分(fēn)任務(wù)甚至已經超過了人類的表現。同時還可(kě)以通過調參進一步提高他(tā)的上限。
優點4:可(kě)移植性好
由于深度學(xué)習的優異表現,有(yǒu)很(hěn)多(duō)框架可(kě)以使用(yòng),例如 TensorFlow、Pytorch。這些框架可(kě)以兼容很(hěn)多(duō)平台。
缺點1:計算量大,便攜性差
深度學(xué)習需要大量的數據很(hěn)大量的算力,所以成本很(hěn)高。并且現在很(hěn)多(duō)應用(yòng)還不适合在移動設備上使用(yòng)。目前已經有(yǒu)很(hěn)多(duō)公(gōng)司和團隊在研發針對便攜設備的芯片。這個問題未來會得到解決。
缺點2:硬件需求高
深度學(xué)習對算力要求很(hěn)高,普通的 CPU 已經無法滿足深度學(xué)習的要求。主流的算力都是使用(yòng) GPU 和 TPU,所以對于硬件的要求很(hěn)高,成本也很(hěn)高。
缺點3:模型設計複雜
深度學(xué)習的模型設計非常複雜,需要投入大量的人力物(wù)力和時間來開發新(xīn)的算法和模型。大部分(fēn)人隻能(néng)使用(yòng)現成的模型。
缺點4:沒有(yǒu)”人性”,容易存在偏見
由于深度學(xué)習依賴數據,并且可(kě)解釋性不高。在訓練數據不平衡的情況下會出現性别歧視、種族歧視等問題。
4種典型的深度學(xué)習算法

卷積神經網絡 - CNN
CNN 的價值:
能(néng)夠将大數據量的圖片有(yǒu)效的降維成小(xiǎo)數據量(并不影響結果)
能(néng)夠保留圖片的特征,類似人類的視覺原理(lǐ)
CNN 的基本原理(lǐ):
卷積層 – 主要作(zuò)用(yòng)是保留圖片的特征
池化層 – 主要作(zuò)用(yòng)是把數據降維,可(kě)以有(yǒu)效的避免過拟合
全連接層 – 根據不同任務(wù)輸出我們想要的結果
CNN 的實際應用(yòng):
圖片分(fēn)類、檢索
目标定位檢測
目标分(fēn)割
人臉識别
骨骼識别
了解更多(duō)《一文(wén)看懂卷積神經網絡-CNN(基本原理(lǐ)+獨特價值+實際應用(yòng))》
循環神經網絡 - RNN
RNN 是一種能(néng)有(yǒu)效的處理(lǐ)序列數據的算法。比如:文(wén)章内容、語音音頻、股票價格走勢…
之所以他(tā)能(néng)處理(lǐ)序列數據,是因為(wèi)在序列中(zhōng)前面的輸入也會影響到後面的輸出,相當于有(yǒu)了“記憶功能(néng)”。但是 RNN 存在嚴重的短期記憶問題,長(cháng)期的數據影響很(hěn)小(xiǎo)(哪怕他(tā)是重要的信息)。
于是基于 RNN 出現了 LSTM 和 GRU 等變種算法。這些變種算法主要有(yǒu)幾個特點:
長(cháng)期信息可(kě)以有(yǒu)效的保留
挑選重要信息保留,不重要的信息會選擇“遺忘”
RNN 幾個典型的應用(yòng)如下:
文(wén)本生成
語音識别
機器翻譯
生成圖像描述
視頻标記
了解更多(duō)《一文(wén)看懂循環神經網絡-RNN(獨特價值+優化算法+實際應用(yòng))》
生成對抗網絡 - GANs
假設一個城市治安(ān)混亂,很(hěn)快,這個城市裏就會出現無數的小(xiǎo)偷。在這些小(xiǎo)偷中(zhōng),有(yǒu)的可(kě)能(néng)是盜竊高手,有(yǒu)的可(kě)能(néng)毫無技(jì )術可(kě)言。假如這個城市開始整饬其治安(ān),突然開展一場打擊犯罪的「運動」,警察們開始恢複城市中(zhōng)的巡邏,很(hěn)快,一批「學(xué)藝不精(jīng)」的小(xiǎo)偷就被捉住了。之所以捉住的是那些沒有(yǒu)技(jì )術含量的小(xiǎo)偷,是因為(wèi)警察們的技(jì )術也不行了,在捉住一批低端小(xiǎo)偷後,城市的治安(ān)水平變得怎樣倒還不好說,但很(hěn)明顯,城市裏小(xiǎo)偷們的平均水平已經大大提高了。
警察們開始繼續訓練自己的破案技(jì )術,開始抓住那些越來越狡猾的小(xiǎo)偷。随着這些職業慣犯們的落網,警察們也練就了特别的本事,他(tā)們能(néng)很(hěn)快能(néng)從一群人中(zhōng)發現可(kě)疑人員,于是上前盤查,并最終逮捕嫌犯;小(xiǎo)偷們的日子也不好過了,因為(wèi)警察們的水平大大提高,如果還想以前那樣表現得鬼鬼祟祟,那麽很(hěn)快就會被警察捉住。為(wèi)了避免被捕,小(xiǎo)偷們努力表現得不那麽「可(kě)疑」,而魔高一尺、道高一丈,警察也在不斷提高自己的水平,争取将小(xiǎo)偷和無辜的普通群衆區(qū)分(fēn)開。随着警察和小(xiǎo)偷之間的這種「交流」與「切磋」,小(xiǎo)偷們都變得非常謹慎,他(tā)們有(yǒu)着極高的偷竊技(jì )巧,表現得跟普通群衆一模一樣,而警察們都練就了「火眼金睛」,一旦發現可(kě)疑人員,就能(néng)馬上發現并及時控制——最終,我們同時得到了最強的小(xiǎo)偷和最強的警察。

了解更多(duō)《什麽是生成對抗網絡 - GAN?(基本概念+工(gōng)作(zuò)原理(lǐ))》
深度強化學(xué)習 - RL
強化學(xué)習算法的思路非常簡單,以遊戲為(wèi)例,如果在遊戲中(zhōng)采取某種策略可(kě)以取得較高的得分(fēn),那麽就進一步「強化」這種策略,以期繼續取得較好的結果。這種策略與日常生活中(zhōng)的各種「績效獎勵」非常類似。我們平時也常常用(yòng)這樣的策略來提高自己的遊戲水平。
在 Flappy bird 這個遊戲中(zhōng),我們需要簡單的點擊操作(zuò)來控制小(xiǎo)鳥,躲過各種水管,飛的越遠(yuǎn)越好,因為(wèi)飛的越遠(yuǎn)就能(néng)獲得更高的積分(fēn)獎勵。
這就是一個典型的強化學(xué)習場景:
機器有(yǒu)一個明确的小(xiǎo)鳥角色——代理(lǐ)
需要控制小(xiǎo)鳥飛的更遠(yuǎn)——目标
整個遊戲過程中(zhōng)需要躲避各種水管——環境
躲避水管的方法是讓小(xiǎo)鳥用(yòng)力飛一下——行動
飛的越遠(yuǎn),就會獲得越多(duō)的積分(fēn)——獎勵
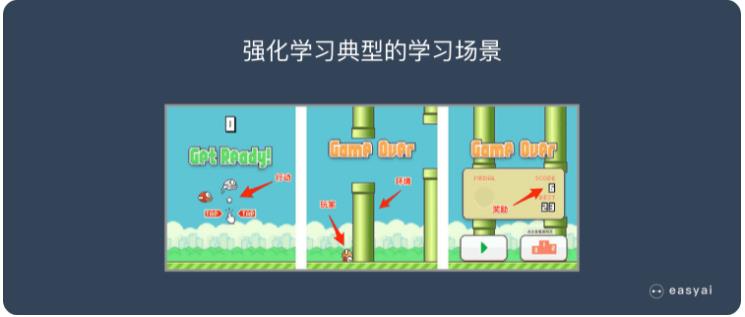
你會發現,強化學(xué)習和監督學(xué)習、無監督學(xué)習 最大的不同就是不需要大量的“數據喂養”。而是通過自己不停的嘗試來學(xué)會某些技(jì )能(néng)。
了解更多(duō):《一文(wén)看懂什麽是強化學(xué)習?(基本概念+應用(yòng)場景+主流算法)》
總結
深度學(xué)習屬于機器學(xué)習的範疇,深度學(xué)習可(kě)以說是在傳統神經網絡基礎上的升級,約等于神經網絡。
深度學(xué)習和傳統機器學(xué)習在數據預處理(lǐ)上都是類似的。核心差别在特征提取環節,深度學(xué)習由機器自己完成特征提取,不需要人工(gōng)提取。
深度學(xué)習的優點:
學(xué)習能(néng)力強
覆蓋範圍廣,适應性好
數據驅動,上限高
可(kě)移植性好
深度學(xué)習的缺點:
計算量大,便攜性差
硬件需求高
模型設計複雜
沒有(yǒu)”人性”,容易存在偏見
深度學(xué)習的4種典型算法:
卷積神經網絡 - CNN
循環神經網絡 - RNN
生成對抗網絡 - GANs
深度強化學(xué)習 - RL
文(wén)章來源于産(chǎn)品經理(lǐ)的 AI 知識庫,作(zuò)者easyAI
