



















































![CCTV-17農業農村 | [中(zhōng)國(guó)三農報道]中(zhōng)國(guó)科(kē)學(xué)院植被病蟲害遙感監測與預測系統升級版發布](static/picture/630c32e37f65b.png)




































以下文(wén)章來源于穿雲尋恒星 ,作(zuò)者Max
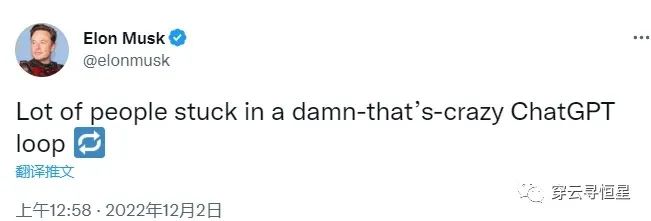
1. 從周五到周末ChatGPT已經瘋傳開來,其對話能(néng)力讓人驚豔。從玩梗、寫詩、寫劇本,到給程序找bug,幫人設計網頁(yè),甚至幫你生成AIGC的提示詞,一副無所不能(néng)的樣子。可(kě)以去Twitter上看Ben Tossell梳理(lǐ)的一些例子,或者自己去試試!一位MBA老師讓ChatGPT回答(dá)自己的管理(lǐ)學(xué)題目,結論是以後不能(néng)再布置可(kě)以帶回家的作(zuò)業了。很(hěn)多(duō)人用(yòng)了以後無法自拔,就如這位所見:
Musk問ChatGPT怎麽設計Twitter(不得不說還挺有(yǒu)創意):
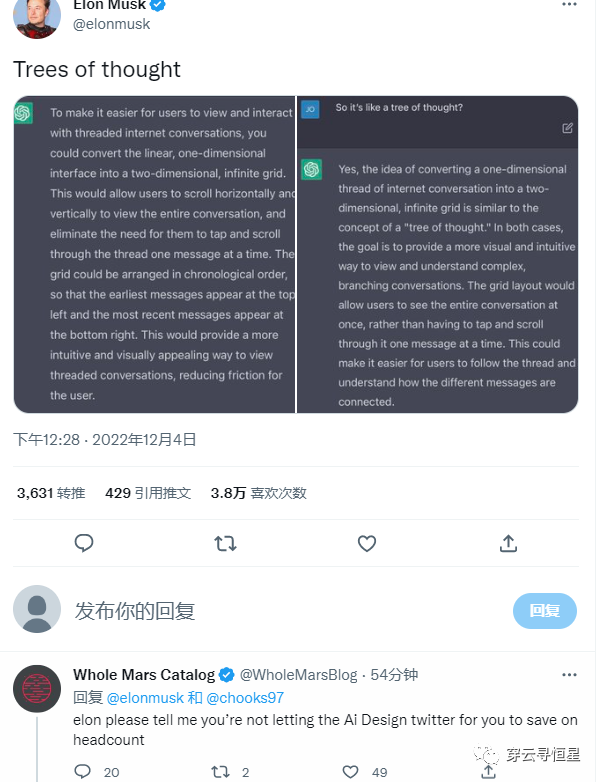
2. 有(yǒu)人讓ChatGPT參加了智商(shāng)測試,得分(fēn)83; SAT測試得分(fēn)1020,對應人類考生52%分(fēn)位。要知道ChatGPT并沒有(yǒu)對數學(xué)方面做過優化,已經是相當不錯的結果了。


3. ChatGPT的提升點

相比之前的GPT-3,ChatGPT的提升點在于能(néng)記住之前的對話,連續對話的感覺讓人舒服。
ChatGPT可(kě)以承認錯誤,如果你認為(wèi)他(tā)的回答(dá)不對,你可(kě)以讓他(tā)改正,并給出更好的答(dá)案。
ChatGPT可(kě)以質(zhì)疑不正确的前提,GPT-3剛發布後很(hěn)多(duō)人測試的體(tǐ)驗并不好,因為(wèi)AI經常創造虛假的内容(隻是話語通順,但脫離實際),而現在再問“哥(gē)倫布2015年來到美國(guó)的情景”這樣的問題,AI已經知道哥(gē)倫布不屬于這個時代了。

ChatGPT還采用(yòng)了注重道德(dé)水平的訓練方式,按照預先設計的道德(dé)準則,對不懷好意的提問和請求“說不”;當然,盡管OpenAI非常小(xiǎo)心,這種準則還是可(kě)能(néng)被聰明的提問方式繞開。
4. ChatGPT的訓練方法
當下大模型的工(gōng)作(zuò)範式是“預訓練-微調”。首先在數據量龐大的公(gōng)開數據集上訓練,然後将其遷移到目标場景中(zhōng)(比如跟人類對話),通過目标場景中(zhōng)的小(xiǎo)數據集進行微調,使模型達到需要的性能(néng)。微調/prompt等工(gōng)作(zuò)從本質(zhì)上對模型改變并不大,但是有(yǒu)可(kě)能(néng)大幅提升模型的實際表現。人類問問題方式對于GPT-3而言不是最自然的理(lǐ)解方式,要麽改造任務(wù),要麽微調模型,總之是讓模型和任務(wù)更加匹配,從而實現更好的效果。
ChatGPT是22年1月推出的InstructGPT的兄弟(dì)模型。InstructGPT增加了人類對模型輸出結果的演示,并且對結果進行了排序,在此基礎上完成訓練,可(kě)以比GPT-3更好的完成人類指令。ChatGPT新(xīn)加入的訓練方式被稱為(wèi)“從人類反饋中(zhōng)強化學(xué)習”(Reinforcement Learning from Human Feedback,RLHF)。
ChatGPT是基于GPT-3.5模型,訓練集基于文(wén)本和代碼,在微軟Azure AI服務(wù)器上完成訓練。原先GPT-3的訓練集隻有(yǒu)文(wén)本,所以這次新(xīn)增了代碼理(lǐ)解和生成的能(néng)力。

5. 為(wèi)什麽ChatGPT的提升這麽明顯
除了帶有(yǒu)記憶能(néng)力、上下文(wén)連續對話能(néng)帶給人顯著的交互體(tǐ)驗提升,ChatGPT的訓練方式也值得關注。上述提到的RLHF方法首見于22年3月發表的論文(wén)(Training language models to follow instructions with human feedback),但根據業界的推測,RLHF并未用(yòng)到InstructGPT的訓練中(zhōng)。InstructGPT所用(yòng)到的text-davinci-002遇到了一些問題,會呈現出模式坍塌(mode collapse)現象,不管問他(tā)什麽問題,經常收斂到同樣的答(dá)案,比如正面情緒相關的回答(dá)都是跟婚禮派對相關。
這次RLHF的方法得以在ChatGPT上應用(yòng),并取得了很(hěn)好的效果。但RLHF實際上并不容易訓練,強化學(xué)習很(hěn)容易遇到模式坍塌,反饋過于稀疏這類問題,訓練起來很(hěn)困難。這可(kě)能(néng)也是為(wèi)什麽論文(wén)在3月發表,ChatGPT在12月才上線(xiàn),中(zhōng)間需要大量的時間來調優。
此外,指令調整(instruction tuning)的貢獻也很(hěn)大。InstructGPT雖然在參數上比GPT-3少了100倍(13億 vs 1750億),它的輸出效果比GPT-3以及用(yòng)監督學(xué)習進行微調的模型都要好得多(duō)。
根據知乎用(yòng)戶“避暑山(shān)莊梁朝偉”的觀點:“Instruction Tuning和Prompt方法的核心一樣,就是去發掘語言模型本身具(jù)備的知識。而他(tā)們的不同點就在于,Prompt是去激發語言模型的補全能(néng)力,比如給出上半句生成下半句、或者做完形填空,都還是像在做language model任務(wù),而Instruction Tuning則是激發語言模型的理(lǐ)解能(néng)力,通過給出更明顯的指令,讓模型去理(lǐ)解并做出正确的反饋。”
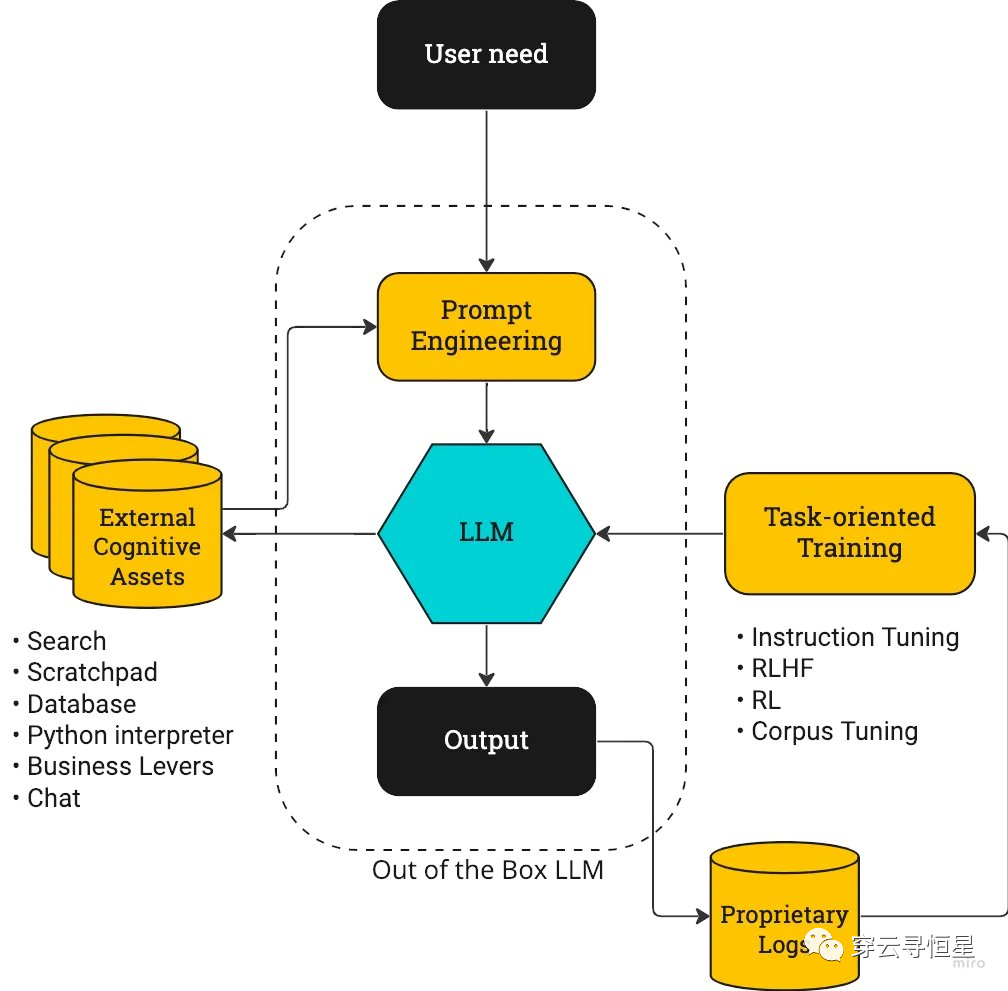
參考下圖,以前大模型的提升重心更多(duō)放在了大模型(LLM)本身和Prompt Engineering上,而ChatGPT的叠代重點是右側的閉環。
action-driven LLM訓練流程圖
最後,ChatGPT在過于保守不提供有(yǒu)效回答(dá)和提供虛假信息之間做出了較好的權衡。之前Meta用(yòng)于科(kē)研的大模型Galactica上線(xiàn)僅3天就被迫下線(xiàn),因為(wèi)提供了過多(duō)虛假的信息。這跟Meta的宣傳策略也有(yǒu)關,其本意是想幫助研究人員整理(lǐ)信息、輔助寫作(zuò),但Meta将其模型宣傳為(wèi)“可(kě)以總結學(xué)術論文(wén),解決數學(xué)問題,生成維基文(wén)章,編寫科(kē)學(xué)代碼,為(wèi)分(fēn)子和蛋白質(zhì)做注解等”,過高期望帶來了反效果,科(kē)研人員本來就是挑剔的。ChatGPT盡管不能(néng)完全避免虛假信息的問題,但可(kě)以看出在微調/Prompt方面做了足夠細緻的工(gōng)作(zuò),一些自相矛盾的提問可(kě)以被甄别出來,讓用(yòng)戶對其回答(dá)更有(yǒu)信心。
6. 商(shāng)業策略也是重要一環
這次ChatGPT是免費不限量向公(gōng)衆開放,用(yòng)戶可(kě)以盡情在平台上嘗試各種奇異瘋狂的想法,而此前GPT-3是根據使用(yòng)量(token)來收費的。在使用(yòng)過程中(zhōng),用(yòng)戶可(kě)以提供反饋,這些反饋是對OpenAI最有(yǒu)價值的信息。OpenAI并不急于創收也不缺錢,坊間傳言最新(xīn)一輪估值已經達到數百億美金,還有(yǒu)金主爸爸微軟。
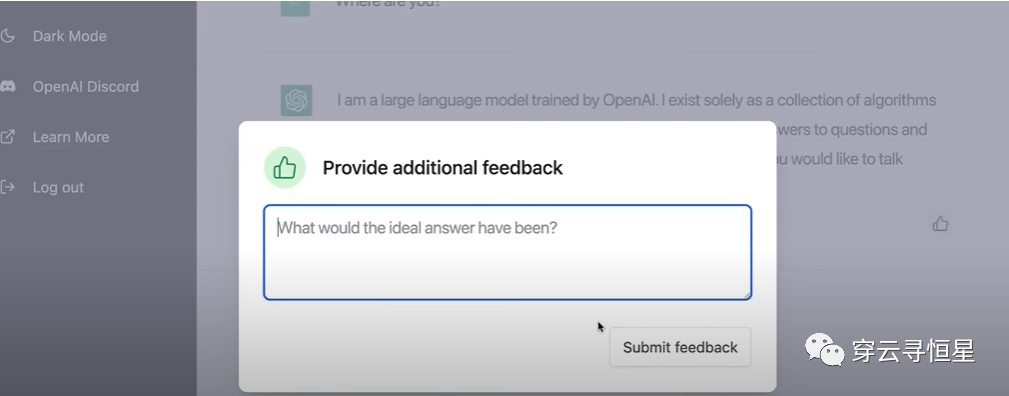
對于AI發展來說,工(gōng)程的重要性實際上大于科(kē)學(xué),創建一個叠代反饋的閉環至關重要。OpenAI很(hěn)注重商(shāng)業應用(yòng),GPT-3已經擁有(yǒu)大量客戶。這些客戶跟OpenAI的反饋互動也是推動進步的關鍵一環。相比之下,谷歌的閉門造車(chē)就顯得不合時宜,或許是缺乏商(shāng)業化的文(wén)化,或許是受限于投入産(chǎn)出比,谷歌對于大模型的應用(yòng)一直很(hěn)“克制”,即便起點很(hěn)高,但如果一直像Waymo做自動駕駛一樣小(xiǎo)規模叠代,早晚會被更為(wèi)開放,獲得更多(duō)數據的企業超越。

7. 後續提升點
RLHF是一種較新(xīn)的方法,随着OpenAI不斷摸索,結合ChatGPT搜集到的用(yòng)戶反饋,模型還有(yǒu)進一步提升的空間。尤其是在道德(dé)/alignment層面,需要屏蔽掉這幾天大家試驗出來的繞過系統限制産(chǎn)生負面信息的方法。
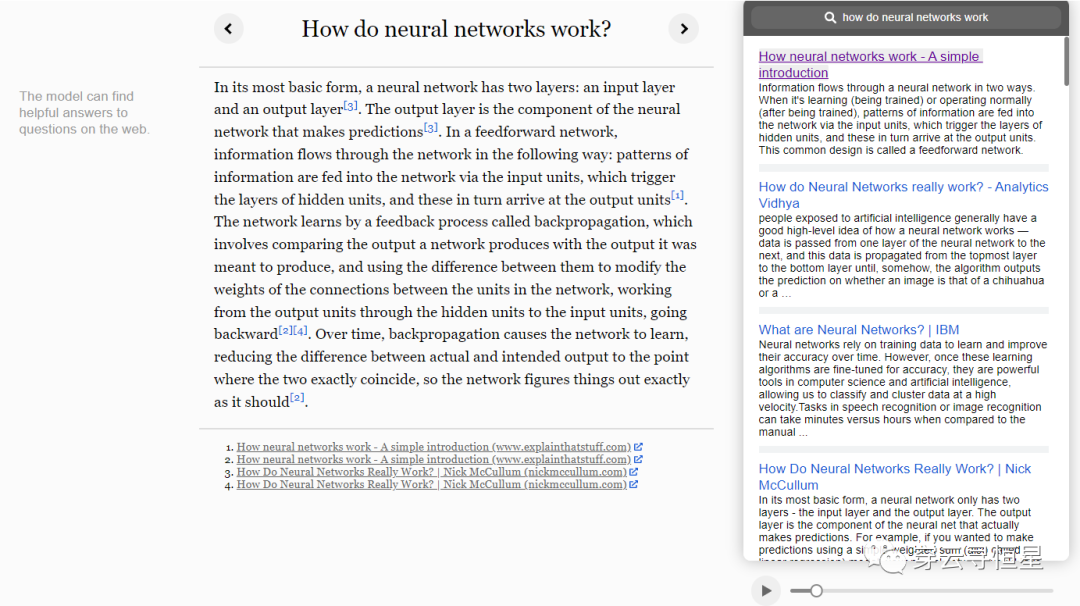
當然也别忘了,OpenAI還有(yǒu)WebGPT這樣的工(gōng)具(jù),可(kě)以理(lǐ)解為(wèi)高階版網頁(yè)爬蟲,從互聯網上摘取信息來回答(dá)問題,并提供相應出處。比如下面的問題How do neural networks work,WebGPT利用(yòng)了GPT-3本身具(jù)備的語義理(lǐ)解能(néng)力和互聯網公(gōng)開信息,自己結合出了一份答(dá)案,不失為(wèi)一種升級的搜索能(néng)力。
在MIT Technology Review對OpenAI科(kē)學(xué)家的采訪中(zhōng),他(tā)們提到了後續有(yǒu)可(kě)能(néng)将ChatGPT和WebGPT的能(néng)力結合起來。有(yǒu)網友挖掘出了ChatGPT内設的提示詞,其中(zhōng)包含browsing:disabled,把浏覽網頁(yè)能(néng)力關閉了,也就是說後續有(yǒu)可(kě)能(néng)加入這個能(néng)力。可(kě)以設想,ChatGPT+WebGPT可(kě)以産(chǎn)生更為(wèi)有(yǒu)意思的結果,信息可(kě)以實時更新(xīn),對于事實真假的判斷将更為(wèi)準确。

與WebGPT的這種結合,對應到上面 action-driven LLM訓練流程圖 的左半部分(fēn),即連接外部的信息源和工(gōng)具(jù)庫。事實上網頁(yè)搜索隻是一種可(kě)能(néng),還結合利用(yòng)各種工(gōng)具(jù)(比如各種辦(bàn)公(gōng)軟件、SaaS軟件),實現更豐富的功能(néng)。
在産(chǎn)品層面,是不是有(yǒu)更好的界面和實現方式也值得讨論。同屏對話框形式容易讓人産(chǎn)生過高的預期,因為(wèi)要保障對話的流暢性。在這一點上,Github Copilot産(chǎn)品就做得很(hěn)好,Copilot主打的是programming pair,以夥伴的身份提出建議。從用(yòng)戶角度,這個建議好就接受,不好就不接受;即便提出了很(hěn)多(duō)不被接受的建議,但在随機時間間隔産(chǎn)生的有(yǒu)效建議帶來的爽感就會讓用(yòng)戶上瘾。如果ChatGPT後續成為(wèi)寫作(zuò)助手、編劇助手、工(gōng)作(zuò)助手等等,類似Copilot的産(chǎn)品形态會容易讓人接受。
寫在最後
很(hěn)多(duō)人驚歎于ChatGPT的能(néng)力,但其實真正驚豔的還在後面。OpenAI最厲害的不是他(tā)關于大模型的理(lǐ)解,而是其工(gōng)程化、叠代反饋的能(néng)力,以及alignment(AI跟人類目标的統一)方面的工(gōng)作(zuò)。很(hěn)欣賞OpenAI CEO Sam Altman的一句話:“Trust the exponential. Flat looking backwards, vertical looking forwards.” 我們就處在即将起飛的這個點上。
